
LISTAGG
Regrouper les données d'une sélection dans un champ résultat unique
Fonction :
La fonction LISTAGG est une fonction d’agrégation qui retourne :
- la concaténation de données extraites par une sous requête
Ou
- la concaténation de données extraites à partir de n enregistrements de la table requêtée par la requête principale
Ceci est particulièrement intéressant pour récupérer et concaténer des données dans un seul champ résultat.
Syntaxe :
La fonction LISTAGG possède plusieurs paramètres :
LISTAGG(DISTINCT/ALL EXPRESSION, SEPARATEUR)
ON OVERFLOW ERROR ou ON OVERFLOW TRUNCATE
WITHIN GROUP(ORDER BY liste des zones de tri)
Paramètres obligatoires :
- EXPRESSION :
- Soit une sous reqête de sélection des champs à extraire.
- Soit une colonne de la table de la requête principale dont les données sont à agréger.
Paramètres facultatifs :
- DISTINCT ou ALL : Gestion des doublons.
- DISTINCT élimine les doublons
- ALL concerve les doublons
Par défaut le paramètre est à ALL.
- SEPARATEUR : permet de définir le ou les caractères qui sépareront les données extraites.
Par défaut, il n’y a pas de séparateur.
- ON OVERFLOW ERROR ou ON OVERFLOW TRUNCATE : permet de gérer le dépacement de capacité de la zone résultats
(si la longueur des données retournées est supérieur à la taille du champ résultat)- ON OVERFLOW ERROR génère une erreur si la longueur des données retournées est supérieur à la taille de la zone résultat
- ON OVERFLOW TRUNCATE : permet de tronquer les données retournées si leur longueur dépasse la taille de la zone résultat.
Les valeurs de ce paramètre peuvent être :- ‘…’ pour que ‘…’ soit ajouté après la derniere valeur agrégée. C’est la valeur par défaut.
- ‘chaine de caractères’ pour que la chaine de caractères définie par l’utilisateur soit ajoutée apèrs la dernière valeur agrégée.
ON OVERFLOW TRUNCATE peut être suivi de :
-
-
- WITH COUNT si l’on souhaite récupérer le nombre de valeurs qui ont été tronquées.
- WITHOUT COUNT si l’on ne souhaite pas récupérer le nombre de valeurs tronquées.
-
Par défaut c’est le WITHOUT COUNT qui est utilisé.
- WITHIN GROUP(ORDER BY liste des zones de tri) : permet de définir l’odre de tri des données agrégées.
Chaque zone de tri peut être suivie des mots clefs :
- ASC si le tri sur cette zone est par ordre croissant
- DESC si le tri sur cette zone est par ordre décroissant
Exemples :
Voici la table CDM_FOOT_1 contenant la liste des pays ayant gagné la coupe du monde de football.
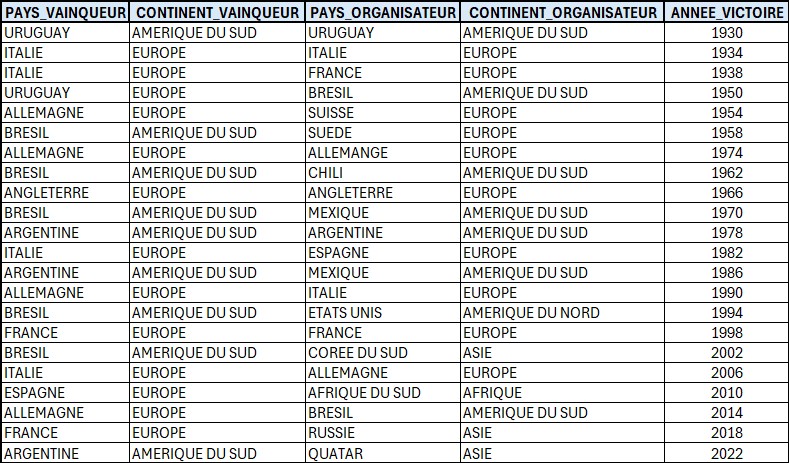
Récupérer la liste agrégée des pays ayant gagné la coupe du monde dans chaque continent organisateur
SELECT CONTINENT_ORGANISATEUR,
LISTAGG(TRIM(PAYS_VAINQUEUR), ‘ – ‘) AS LISTE_PAYS_VAINQUEUR
FROM CDM_FOOT_1
GROUP BY CONTINENT_ORGANISATEUR
ORDER BY CONTINENT_ORGANISATEUR;

Chaque continent organisateur est bien suivi de la liste agrégée des pays vainqueurs séparés par ‘ – ‘. Mais cette liste n’est pas triée.
Récupérer la liste agrégée des pays ayant gagné la coupe du monde dans chaque continent organisateur en la triant par ordre aphabétique
SELECT CONTINENT_ORGANISATEUR,
LISTAGG(TRIM(PAYS_VAINQUEUR), ‘ – ‘)
WITHIN GROUP(ORDER BY PAYS_VAINQUEUR ASC) AS LISTE_PAYS_VAINQUEUR
FROM CDM_FOOT_1
GROUP BY CONTINENT_ORGANISATEUR
ORDER BY CONTINENT_ORGANISATEUR;

Chaque continent organisateur est bien suivi de la liste agrégée des pays vainqueurs séparés par ‘ -‘. et trièe par ordre aplhabétique.
Mais la liste contient des doublons.
Récupérer la liste agrégée des pays ayant gagné la coupe du monde dans chaque continent organisateur en la triant par ordre aphabétique
et en supprimant les doublons
SELECT CONTINENT_ORGANISATEUR,
LISTAGG( DISTINCT TRIM(PAYS_VAINQUEUR), ‘ – ‘)
WITHIN GROUP(ORDER BY PAYS_VAINQUEUR ASC) AS LISTE_PAYS_VAINQUEUR
FROM CDM_FOOT_1
GROUP BY CONTINENT_ORGANISATEUR
ORDER BY CONTINENT_ORGANISATEUR;

Il est également possible d’agréger plusieurs informations.
Récupérer la liste agrégée des pays ayant gagné la coupe du monde dans chaque continent organisateur et l’année de chaque vitoire en triant la liste résultat par année de victoire
SELECT CONTINENT_ORGANISATEUR,
LISTAGG(TRIM(PAYS_VAINQUEUR) CONCAT ‘(‘ CONCAT ANNEE_VICTOIRE CONCAT ‘)’, ‘ – ‘)
WITHIN GROUP(ORDER BY ANNEE_VICTOIRE DESC) AS LISTE_PAYS_VAINQUEUR
FROM CDM_FOOT_1
GROUP BY CONTINENT_ORGANISATEUR
ORDER BY CONTINENT_ORGANISATEUR;

Pour illustrer l’utilisation du paramètre ON OVERFLOW nous allons lister les services de QSYS2.
Ceci pour que la longueur des données afrégées dépasse les 4000 caractères.
SELECT LISTAGG( TRIM(SERVICE_CATEGORY) CONCAT ‘-‘ CONCAT TRIM(SERVICE_NAME), ‘ / ‘)
WITHIN GROUP(ORDER BY SERVICE_CATEGORY, SERVICE_NAME) AS LISTE_SERVICES
, CURRENT_USER AS USER
FROM QSYS2.SERVICES_INFO;
Cette requête avec les paramètres ON OVERFLOW par défaut équivaut à la requête suivante :
SELECT LISTAGG( TRIM(SERVICE_CATEGORY) CONCAT ‘-‘ CONCAT TRIM(SERVICE_NAME), ‘ / ‘
ON OVERFLOW TRUNCATE ‘…’ WITH COUNT)
WITHIN GROUP(ORDER BY SERVICE_CATEGORY, SERVICE_NAME) AS LISTE_SERVICES
, CURRENT_USER AS USER
FROM QSYS2.SERVICES_INFO;
Les caractères ‘…’ indiquent que les données du champs résultats ont été tronquées.
Le (285) indique que 285 valeurs n’ont pas pu être intégrées au champ résultat.
Voici deux autres exemples d’utilisation du paramètre ON OVERFLOW
Avec le libellé ‘FIN TRONQUEE…’ et sans le compteur de données tronquées :
SELECT LISTAGG( TRIM(SERVICE_CATEGORY) CONCAT ‘-‘ CONCAT TRIM(SERVICE_NAME), ‘ / ‘
ON OVERFLOW TRUNCATE ‘FIN TRONQUEE…’ WITHOUT COUNT)
WITHIN GROUP(ORDER BY SERVICE_CATEGORY, SERVICE_NAME) AS LISTE_SERVICES
, CURRENT_USER AS USER
FROM QSYS2.SERVICES_INFO;
Avec le libellé ‘FIN TRONQUEE…’ et le compteur de données tronquées :
SELECT LISTAGG( TRIM(SERVICE_CATEGORY) CONCAT ‘-‘ CONCAT TRIM(SERVICE_NAME), ‘ / ‘
ON OVERFLOW TRUNCATE ‘FIN TRONQUEE…’ WITH COUNT)
WITHIN GROUP(ORDER BY SERVICE_CATEGORY, SERVICE_NAME) AS LISTE_SERVICES
, CURRENT_USER AS USER
FROM QSYS2.SERVICES_INFO;
Le libellé ‘FIN TRONQUEE…’ est bien affiché ainsi que le nombre de données tronquées.