
RANK et DENSE_RANK
Extraire des enregistrements en fonction du classement des valeurs d'un champ
Fonction :
Les fonctions OLAP SQL : RANK et DENSE_RANK permettent de définir un classement (= un rang) des enregistrements d’une table en fonction des valeurs d’un ou plusieurs champs donnés.
Ces fonctions sont particulièrement utiles lorsque l’on souhaite extraire les enregistrements ayant la plus grande (ou la plus petite) valeur d’un champ pour chaque sous groupe d’enregistrements de la table.
En effet, lorsque l’on souhaite extraire l’enregistrement ayant la plus grande (ou la plus petite) valeur dans un champ, un tri avec ORDER BY est suffisant.
Mais si l’on souhaite extraire les enregistrements ayant la plus grande (ou la plus petite) valeur dans un champ pour chaque sous groupe d’enregistrements d’une table, la clause ORDER BY ne suffira pas.
Les fonctions RANK et DENSE_RANK, grâce au paramètre PARTITION BY, pourront, elles, répondre à ce besoin.
La différence entre la fonction RANK et la fonction DENSE_RANK réside dans la façon dont sont prises en compte les égalités de rangs
(voir l’exemple 2 ci-dessous).
Syntaxe :
Les fonctions RANK et DENSE_RANK sont suivies de la clause OVER() avec 2 les paramètres suivants :
- PARTITION BY + la liste des champs composant une partition de la table traitée.
Ce paramètre est facultatif.
Il permet de découper la table traitée en différentes partitions.
Ceci pour éviter qu’un RANK sur une partition ne prenne en compte les rangs définis sur une autre partition. - ORDER BY + la liste des champs définissant le classement à prendre en compte, suivi de ASC si le tri doit être par ordre croissant (valeur par défaut) ou par DESC si le tri doit être par ordre décroissant.
Ce paramètre est obligatoire.
Et enfin les fonctions RANK et DENSE_RANK se terminent par AS suivi du nom du nouveau champ de rang qu’elles génèrent.
RANK() OVER(PARTITION BY ma_zone_de_partitionnement ORDER BY ma_zone_de_classement ASC) AS nouveau_champ_de_rang
DENSE_RANK() OVER(PARTITION BY ma_zone_de_partitionnement ORDER BY ma_zone_de_classement DESC) AS nouveau_champ_de_rang
Exemples :
Exemple 1 : principes de base
Voici la table CDM_FOOT contenant la liste des pays ayant gagné la coupe du monde de football au moins une fois :
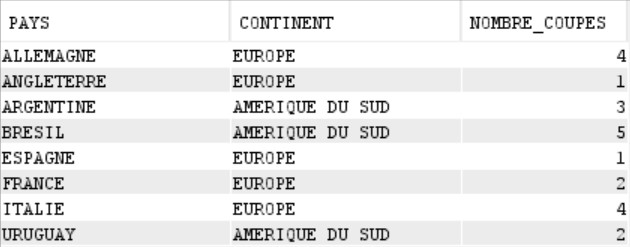
Pour extraire le PAYS qui a remporté le plus de coupes, un ORDER BY suffira :
SELECT * FROM CDM_FOOT ORDER BY NOMBRE_COUPES DESC LIMIT 1;
Mais pour extraire les pays qui ont gagné le plus de coupes pour chaque continent, il faudra utiliser les fonctions RANK ou DENSE_RANK :
WITH CTE_CLASSEMENT AS(
SELECT PAYS, CONTINENT, NOMBRE_COUPES,
RANK() OVER(PARTITION BY CONTINENT ORDER BY NOMBRE_COUPES DESC) AS CLASSEMENT_RANK
FROM CDM_FOOT
)
SELECT * FROM CTE_CLASSEMENT WHERE CLASSEMENT_RANK = 1;
On récupère bien pour chaque CONTINENT, le pays ayant remporté le plus de coupes.
En cas d’égalité, les enregistrements obtenant le même classement ressortent car le même rang leur a été attribué.
Exemple 2 : différence entre la fonction RANK et la fonction DENSE_RANK
Lorsque plusieurs enregistrements ont un rang identique :
- RANK reprend la suite du classement en prenant en compte le nombre d’enregistrements de rang identique.
- DENSE_RANK reprend la suite du classement sans tenir compte du nombre d’enregistrements de rang identique.
SELECT PAYS, CONTINENT, NOMBRE_COUPES,
RANK() OVER(PARTITION BY CONTINENT ORDER BY NOMBRE_COUPES DESC) AS CLASSEMENT_RANK,
DENSE_RANK() OVER(PARTITION BY CONTINENT ORDER BY NOMBRE_COUPES DESC) AS CLASSEMENT_DENSE_RANK
FROM CDM_FOOT;