
Créer un fichier à partir des données d'un spool avec SQL
Objectifs :
Il est, parfois, intéressant de pouvoir récupérer des données à partir de fichiers édités (spool file).
C’est le cas lorsqu’il faut récupérer les données extraites par des commandes CL génèrant une édition (OUTPUT *PRINT) où lorsqu’il faut analyser des spools générés par d’autres traitements.
Ceci est facilement réalisable avec SQL.
Pour cela, 3 étapes sont nécessaires :
- Rechercher et identifier le spool à traiter.
- Extraire les données du spool à traiter.
- Générer un fichier avec les données du spool mises en forme.
Identification du spool à traiter :
La fonction table QSYS2.SPOOLED_FILE_INFO permet de lister les spools présents sur une machine.
Elle permet donc de récupérer les identifiants d’un spool spécifique.
Ce sont ces identifiants qui seront ensuite utilisés pour cibler le spool à traiter.
Les identifiants d’un fichier spool, portés par la fonction table QSYS2.SPOOLED_FILE_INFO, sont :
- SPOOLED_FILE_NAME : Nom du fichier spool
- SPOOLED_FILE_NUMBER : Numéro du spool
- QUALIFIED_JOB_NAME : Identifiant complet du job ayant généré le spool.
Cet identifiant est composé ainsi : Numéro du job / Utilisateur du job / Nom du job - JOB_NAME : Nom du job
- JOB_USER : Utilisateur du job
- JOB_NUMBER : Numéro du job
Exemples d’utilisation de la fonction table QSYS2.SPOOLED_FILE_INFO :
- Lister tous les spools de la machine
SELECT
SPOOLED_FILE_NAME,
SPOOLED_FILE_NUMBER,
STATUS,
TOTAL_PAGES,
QUALIFIED_JOB_NAME,
JOB_NAME,
JOB_USER,
JOB_NUMBER,
OUTPUT_QUEUE,
OUTPUT_QUEUE_LIBRARY
FROM TABLE(QSYS2.SPOOLED_FILE_INFO(USER_NAME => ‘*ALL’)); - Lister tous les spools de l’utilisateur en cours
SELECT
SPOOLED_FILE_NAME,
SPOOLED_FILE_NUMBER,
STATUS,
TOTAL_PAGES,
QUALIFIED_JOB_NAME,
JOB_NAME,
JOB_USER,
JOB_NUMBER,
OUTPUT_QUEUE,
OUTPUT_QUEUE_LIBRARY
FROM TABLE(QSYS2.SPOOLED_FILE_INFO(USER_NAME => ‘*CURRENT’)); - Lister tous les spools d’un utilisateur donné, par exemple les spools de l’utilisateur mon_user
SELECT
SPOOLED_FILE_NAME,
SPOOLED_FILE_NUMBER,
STATUS,
TOTAL_PAGES,
QUALIFIED_JOB_NAME,
JOB_NAME,
JOB_USER,
JOB_NUMBER,
OUTPUT_QUEUE,
OUTPUT_QUEUE_LIBRARY
FROM TABLE(QSYS2.SPOOLED_FILE_INFO(USER_NAME => ‘mon_user‘)); - Lister tous les spools du job en cours
SELECT
SPOOLED_FILE_NAME,
SPOOLED_FILE_NUMBER,
STATUS,
TOTAL_PAGES,
QUALIFIED_JOB_NAME,
JOB_NAME,
JOB_USER,
JOB_NUMBER,
OUTPUT_QUEUE,
OUTPUT_QUEUE_LIBRARY
FROM TABLE(QSYS2.SPOOLED_FILE_INFO(JOB_NAME => ‘*’)); - Lister tous les spools d’un job donné
Exemple pour le job :
JOB_NAME : mon_job_name
JOB_USER : mon_job_user
JOB_NUMBER : mon_job_number
SELECT
SPOOLED_FILE_NAME,
SPOOLED_FILE_NUMBER,
STATUS,
TOTAL_PAGES,
QUALIFIED_JOB_NAME,
JOB_NAME,
JOB_USER,
JOB_NUMBER,
OUTPUT_QUEUE,
OUTPUT_QUEUE_LIBRARY
FROM TABLE(QSYS2.SPOOLED_FILE_INFO(JOB_NAME => ‘*ALL’))
WHERE QUALIFIED_JOB_NAME = ‘mon_job_number/mon_job_user/mon_job_name‘);Ou
SELECT
SPOOLED_FILE_NAME,
SPOOLED_FILE_NUMBER,
STATUS,
TOTAL_PAGES,
QUALIFIED_JOB_NAME,
JOB_NAME,
JOB_USER,
JOB_NUMBER,
OUTPUT_QUEUE,
OUTPUT_QUEUE_LIBRARY
FROM TABLE(QSYS2.SPOOLED_FILE_INFO(JOB_NAME => ‘*ALL’))
WHERE JOB_NUMBER = mon_job_number
AND JOB_USER = ‘mon_job_user‘
AND JOB_NAME = ‘mon_job_name‘; Récupérer le dernier spool généré par un job donné
Exemple pour le job :
JOB_NAME : mon_job_name
JOB_USER : mon_job_user
JOB_NUMBER : mon_job_numberSELECT
SPOOLED_FILE_NAME,
SPOOLED_FILE_NUMBER,
STATUS,
TOTAL_PAGES,
QUALIFIED_JOB_NAME,
JOB_NAME,
JOB_USER,
JOB_NUMBER,
OUTPUT_QUEUE,
OUTPUT_QUEUE_LIBRARY
FROM TABLE(QSYS2.SPOOLED_FILE_INFO(JOB_NAME => ‘*ALL’))
WHERE JOB_NUMBER = mon_job_number
AND JOB_USER = ‘mon_job_user‘
AND JOB_NAME = ‘mon_job_name‘
ORDER BY CREATION_TIMESTAMP DESC
FETCH FIRST 1 ROW ONLY;
Extraction des données du spool à traiter :
Une fois le spool à traité identifier, il suffit de requêter la fonction table SYSTOOLS.SPOOLED_FILE_DATA pour récupérer les données du spool.
La fonction table SYSTOOLS.SPOOLED_FILE_DATA ne contient que 2 champs :
- ORDINAL_POSITION : qui correspond au numéro de ligne éditée (sans prise en compte des sauts de lignes ou des sauts de pages)
- SPOOLED_DATA : qui correspond au contenu de la ligne éditée
Pour cibler le spool à traiter lors de la réquête sur la table fonction SYSTOOLS.SPOOLED_FILE_DATA il faut utiliser les identifiants suivants :
- JOB_NAME : qui correspond au QUALIFIED_JOB_NAME récupérer dans la fonction table QSYS2.SPOOLED_FILE_INFO.
C’est à dire : Numéro du Job + ‘/’ + Utilisateur du Job + ‘/’ Nom du Job - SPOOLED_FILE_NAME : nom du spool.
C’est le nom du spool récupérer avec la fonction table QSYS2.SPOOLED_FILE_INFO. - SPOOLED_FILE_NUMBER : numéro du spool.
Il est lui aussi récupéré depuis la fonction table QSYS2.SPOOLED_FILE_INFO.
Exemple avec le fichier spool suivant :
JOB_NAME : mon_job_name
JOB_USER : mon_job_user
JOB_NUMBER : mon_job_number
SPOOLED_FILE_NAME : mon_spooled_file_name
SPOOLED_FILE_NUMBER : mon_spooled_file_number
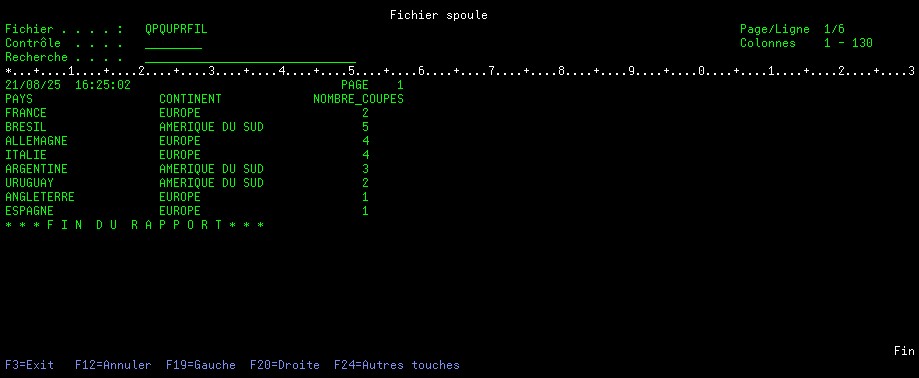
SELECT ORDINAL_POSITION, SPOOLED_DATA
FROM TABLE(SYSTOOLS.SPOOLED_FILE_DATA(JOB_NAME => ‘mon_job_number/mon_job_user/mon_job_name‘, SPOOLED_FILE_NAME =>’mon_spooled_file_name‘, SPOOLED_FILE_NUMBER => mon_spooled_file_number))
ORDER BY ORDINAL_POSITION;
Le résultat obtenu est :
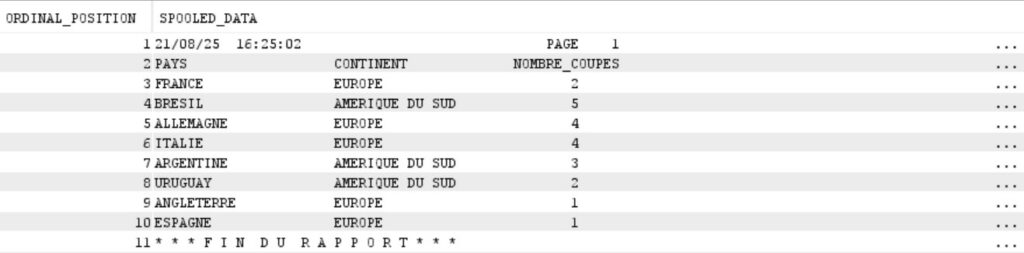
Le résultat obtenu correspond totalement au données éditées.
Mais il est peu exploitable car :
- le champ SPOOLED_DATA contient l’intégralité de la ligne éditée
- Les lignes 1 et 11 sont des lignes propres à l’édition (Date, N° de page, ligne de fin d’édition) qu’il n’est peut-etre pas utile d’extraire.
Génération d'une table à partir des données du spool mises en forme
Les données du spool étant extractables, il ne reste plus qu’à les mettre en forme et à faire un CREATE TABLE pour générer une table propre avec les données issues du spool.
Exemple avec les données du spool précédent :
- Suppression du fichier à générer
DROP TABLE QTEMP.TB_SPOOL; - Création de la table avec définition des champs à extraire de SPOOLED_DATA
CREATE TABLE QTEMP.TB_SPOOL (
PAYS CHARACTER (20) NOT NULL WITH DEFAULT,
CONTINENT CHARACTER (20) NOT NULL WITH DEFAULT,
NOMBRE_COUPE CHARACTER (1) NOT NULL WITH DEFAULT); - Alimentation de la table à partir des donnés récupérées dans le champ SPOOLED_DATA (découpé avec des substring : SUBSTR)
INSERT INTO QTEMP.TB_SPOOL (PAYS, CONTINENT, NOMBRE_COUPE)
SELECT SUBSTR(SPOOLED_DATA, 1, 20),
SUBSTR(SPOOLED_DATA, 23, 20),
SUBSTR(SPOOLED_DATA, 52, 1)
FROM TABLE(SYSTOOLS.SPOOLED_FILE_DATAJOB_NAME => ‘mon_job_number/mon_job_user/mon_job_name‘, SPOOLED_FILE_NAME =>’mon_spooled_file_name‘, SPOOLED_FILE_NUMBER => mon_spooled_file_number))
WHERE SUBSTR(SPOOLED_DATA, 49, 4) <> ‘PAGE’
AND SUBSTR(SPOOLED_DATA, 1, 37) <> ‘* * * F I N D U R A P P O R T * * *’
AND SUBSTR(SPOOLED_DATA, 1, 4) <> ‘PAYS’
ORDER BY ORDINAL_POSITION; - Vérification de la table générée
SELECT *
FROM QTEMP.TB_SPOOL;
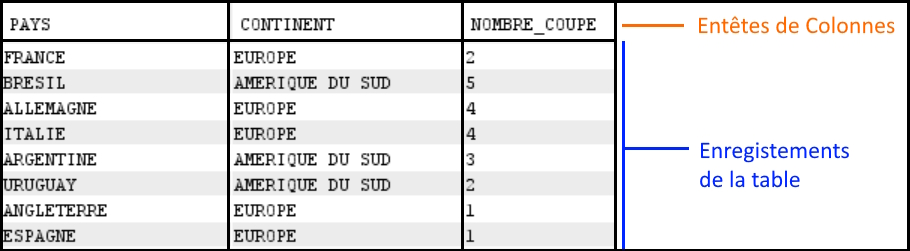
Le résultat obtenu est une table totalement exploitable, avec 3 champs distincts : PAYS, CONTINENT, NOMBRE_COUPE.